자연어 처리(NLP)(Natural Language Processing)의 기초 개념부터 최신 트랜스포머 모델까지 상세히 알아봅니다. Word2Vec, BERT, GPT 등 핵심 기술의 작동 원리와 실제 활용 사례를 통해 AI의 언어 이해 능력을 향상시키는 방법을 자세히 설명합니다. 특히 한국어 처리를 위한 특화 기술과 최신 개발 동향을 포함한 완벽 가이드.
ChatGPT 시대의 NLP 기술: 기본 원리부터 실무 활용까지
자연어 처리(NLP)는 인공지능의 핵심 분야로 자리잡았습니다. 특히 ChatGPT와 같은 대화형 AI의 등장으로, NLP 기술은 우리의 일상생활에 깊숙이 파고들었죠. 하지만 많은 분들이 NLP의 기본 원리와 발전 과정을 제대로 이해하지 못한 채 사용하고 계신데요. 오늘은 NLP의 기초부터 최신 기술까지, 실제 활용 사례를 중심으로 자세히 알아보도록 하겠습니다.

AI시대의 NLP 기술
NLP의 기본 개념
자연어 처리(NLP, Natural Language Processing)는 인공지능(AI)의 핵심 분야로, 인간이 사용하는 자연어를 컴퓨터가 이해하고 처리할 수 있도록 하는 기술입니다. 이는 언어의 의미를 해석하고, 텍스트나 음성을 기반으로 의사소통하거나 작업을 수행하는 데 초점을 맞춥니다. NLP는 언어학, 컴퓨터 과학, 데이터 과학이 결합된 학문으로, 인간의 언어를 기계적으로 처리하기 위해 다양한 알고리즘과 모델을 활용합니다.
NLP의 주요 목표
- 언어 이해: 텍스트나 음성 데이터를 분석해 그 의미를 정확히 파악.
- 언어 생성: 사람이 작성한 것처럼 자연스럽고 문맥에 맞는 텍스트 생성.
- 정보 추출 및 요약: 방대한 데이터에서 핵심 정보를 추출하거나 요약.
- 번역 및 대화: 다국어 번역과 대화형 AI 개발.
NLP의 실제 활용 사례
- 챗봇과 가상 비서: 고객 서비스 및 개인 비서 역할 수행(Siri, Alexa 등).
- 기계 번역: Google Translate와 같은 실시간 번역 서비스 제공.
- 감성 분석: 소셜 미디어나 리뷰 데이터를 분석해 소비자 감정을 파악.
- 헬스케어: 의료 기록 분석 및 질병 예측 지원.
1. NLP의 기본 원리와 발전 과정
자연어 처리의 기초: 텍스트 전처리와 형태소 분석
텍스트 데이터를 다루기 위해서는 먼저 ‘전처리’ 과정이 필요합니다. 문장을 의미 있는 단위로 나누고, 불필요한 기호나 공백을 제거하는 작업이죠. 한국어의 경우 특히 복잡한 문법 구조 때문에 형태소 분석이 매우 중요합니다. ‘나는 학교에 갔다’라는 문장을 예로 들면, ‘나/는/학교/에/가/았/다’와 같이 최소 의미 단위로 분리하는 과정이 필요하죠.
형태소 분석기술은 꾸준히 발전해왔는데요. 초기에는 규칙 기반으로 시작했지만, 현재는 딥러닝 기술을 활용해 더욱 정확한 분석이 가능해졌습니다. KoNLPy, Mecab과 같은 한국어 형태소 분석기들이 대표적인 예시입니다.
텍스트 데이터를 분석하기 위한 첫 단계는 ‘전처리’ 과정입니다. 이는 마치 요리를 하기 전 재료를 손질하는 것과 같은데요. 구체적으로는 다음과 같은 과정을 거칩니다:
- 토큰화(Tokenization)
- 문장을 의미 있는 단위로 분리
- 한국어의 경우: ‘나는 학교에 갔다’ → ‘나/는/학교/에/가/았/다’
- 영어의 경우: “I am going to school” → “I/am/going/to/school”
- 정규화(Normalization)
- 불필요한 특수문자 제거
- 대소문자 통일
- 띄어쓰기 보정
- 품사 태깅(POS Tagging)
- 각 단어의 품사 정보 부여
- 예: ‘나(대명사)/는(조사)/학교(명사)/에(조사)/갔다(동사)’
임베딩 기술의 혁신: Word2Vec에서 BERT까지
단어의 의미를 컴퓨터가 이해할 수 있는 숫자 벡터로 변환하는 ‘임베딩’ 기술은 NLP의 핵심입니다. 2013년 구글이 발표한 Word2Vec은 획기적인 전환점이 되었는데요. ‘왕 – 남자 + 여자 = 여왕’과 같은 단어 간의 의미적 관계를 벡터 연산으로 표현할 수 있게 되었죠.
이후 등장한 BERT(Bidirectional Encoder Representations from Transformers)는 더 큰 혁신을 가져왔습니다. 문맥을 양방향으로 이해하면서, 같은 단어라도 문맥에 따라 다른 의미를 가질 수 있다는 점을 학습할 수 있게 된 것이죠. ‘배가 아프다’와 ‘배를 타다’에서 ‘배’의 의미가 다르다는 것을 이해할 수 있게 된 겁니다.
단어를 컴퓨터가 이해할 수 있는 숫자 벡터로 변환하는 과정을 ‘임베딩’이라고 합니다. 이 기술은 다음과 같이 발전해왔습니다:
- Word2Vec (2013)
- 구글이 개발한 혁신적인 단어 임베딩 기술
- 단어 간의 의미적 관계를 벡터 연산으로 표현
- 예: ‘왕 – 남자 + 여자 = 여왕’과 같은 유추가 가능
- GloVe (2014)
- 스탠포드 대학에서 개발
- 전체 말뭉치의 통계 정보를 활용
- Word2Vec보다 더 풍부한 의미 관계 포착
- BERT (2018)
- 구글이 개발한 양방향 인코더
- 문맥을 고려한 동적 임베딩 생성
- 동음이의어 구분 가능 (예: ‘배’가 과일인지, 운송수단인지 구분)
2.트랜스포머와 어텐션 메커니즘의 등장
2017년 구글이 발표한 ‘트랜스포머’ 구조는 NLP 역사에서 가장 중요한 혁신 중 하나입니다. 기존의 순차적 처리 방식에서 벗어나, 문장 내 모든 단어들 간의 관계를 한 번에 고려할 수 있게 되었죠. 특히 ‘어텐션 메커니즘’은 문장에서 중요한 부분에 더 집중할 수 있게 해주었습니다.
트랜스포머의 개념과 배경
트랜스포머는 입력 데이터(예: 문장)를 시퀀스 형태로 받아들여 이를 다른 시퀀스로 변환하는 딥러닝 모델입니다. 기존 RNN이나 LSTM 모델은 순차적으로 데이터를 처리했지만, 트랜스포머는 어텐션 메커니즘을 활용해 입력 시퀀스 내 모든 단어 간의 관계를 병렬적으로 학습합니다. 이를 통해 다음과 같은 주요 문제를 해결했습니다:
- 병렬 처리 가능: RNN 기반 모델은 순차적으로 데이터를 처리해야 하므로 학습 속도가 느렸습니다. 반면 트랜스포머는 병렬 처리가 가능해 대규모 데이터 학습에 적합합니다.
- 장거리 의존성 문제 해결: 긴 문장에서 멀리 떨어진 단어들 간의 관계를 효과적으로 학습할 수 있습니다.
이 기술을 기반으로 GPT, BERT와 같은 강력한 언어 모델들이 등장했고, 현재의 ChatGPT까지 이어지게 되었습니다. 특히 한국어 처리를 위한 KoBERT, KoGPT 등의 모델도 개발되어, 우리말에 특화된 성능을 보여주고 있죠.
2017년 등장한 트랜스포머 구조는 NLP 분야에 혁명적인 변화를 가져왔습니다:
- 어텐션 메커니즘의 특징
- 문장 내 모든 단어 간의 관계를 동시에 고려
- 중요한 정보에 더 많은 ‘주의’를 기울임
- 장거리 의존성 문제 해결
- 트랜스포머 기반 모델들
- GPT 시리즈: 자연스러운 텍스트 생성
- BERT: 문맥 이해와 질의응답
- T5: 다양한 NLP 태스크 통합 처리
- 한국어 특화 모델
- KoBERT: SK텔레콤이 개발한 한국어 BERT
- KoGPT: 한국어에 최적화된 생성형 모델
- KoBART: 한국어 텍스트 요약과 생성
3. 최신 NLP 기술의 실제 응용 사례
2024년 기준으로 자연어 처리(NLP) 기술의 주요 응용 분야별 사용 비율은 다음과 같습니다.
가장 큰 비중을 차지하는 응용 분야는 챗봇과 가상 비서로, 전체의 30%를 차지합니다. 이는 고객 서비스와 개인화된 사용자 경험을 제공하는 데 중요한 역할을 하고 있습니다. 그다음으로는 기계 번역이 25%로 높은 비중을 보이며, 글로벌 커뮤니케이션과 다국어 지원에서 필수적인 도구로 자리 잡고 있습니다.
감성 분석은 20%를 차지하며, 주로 소셜 미디어와 고객 리뷰 데이터를 분석하여 기업의 마케팅 전략 최적화와 브랜드 평판 관리를 지원합니다. 헬스케어 분야는 NLP 응용의 15%를 차지하며, 의료 데이터 분석, 진단 지원, 환자 관리 등에서 널리 활용되고 있습니다. 마지막으로 자동 요약은 10%로 가장 낮은 비율을 보이지만, 문서 요약 및 정보 처리 효율성을 높이는 데 중요한 역할을 하고 있습니다.
이러한 분포는 NLP 기술이 다양한 산업에서 어떻게 활용되고 있는지를 보여주며, 특히 챗봇과 기계 번역이 가장 큰 비중을 차지하고 있음을 강조합니다.
자연어 처리(NLP) 기술은 다양한 산업과 일상에서 중요한 역할을 하고 있으며, 2024년 기준으로 여러 응용 분야에서 활발히 사용되고 있습니다. 아래는 주요 응용 사례를 정리한 내용입니다.
1. 챗봇과 가상 비서
- 기능: 사용자 질문에 자연스럽게 답변하고 대화를 이어가는 기술.
- 대표 사례:
- 아마존 Alexa: 스마트홈 제어, 쇼핑 지원.
- 애플 Siri: 음성 명령을 통한 일정 관리 및 정보 검색.
- 구글 어시스턴트: 다국어 지원과 문맥 기반 대화.
- 효과: 고객 서비스의 효율성을 높이고 개인화된 사용자 경험 제공.
2. 기계 번역
- 기술 기반: 트랜스포머 모델(GPT, BERT 등)을 활용해 문맥을 이해하고 자연스러운 번역 제공.
- 대표 사례:
- 구글 번역: 109개 언어 지원.
- 네이버 파파고: 아시아 언어 특화 번역.
- DeepL: 전문 문서 번역.
- 발전: 신경망 기계 번역(NMT)은 문맥과 뉘앙스를 반영하며 문화적 차이를 이해하는 데도 진보를 이루고 있음.
3. 감성 분석
- 기능: 텍스트에서 긍정적, 부정적, 중립적 감정을 분류.
- 활용 분야:
- 소셜 미디어 모니터링: 브랜드 평판 관리 및 트렌드 분석.
- 고객 리뷰 분석: 제품 개선 및 마케팅 전략 최적화.
- 효과: 기업이 실시간으로 고객 피드백을 분석해 마케팅 전략을 최적화할 수 있음.
4. 헬스케어
- 응용 사례:
- 전자의료기록(EMR) 분석 및 질병 예측.
- 환자 상담 기록 자동화 및 의료 데이터에서 중요한 정보 추출.
- 효과:
- 의료 서비스 품질 향상.
- 환자 관리 효율성 증대와 의료진 업무 부담 감소.
5. 자동 요약
- 기능: 긴 텍스트에서 핵심 정보를 추출하여 간결하게 요약.
- 활용 분야:
- 뉴스 기사 요약.
- 연구 논문 요약.
- 이메일 요약 등.
- 효과: 정보 과부하를 줄이고 효율적인 의사결정을 지원.
6. 검색 엔진 최적화
- 기능: 사용자의 의도를 파악하고 관련성 높은 결과를 제공.
- 대표 사례:
- 구글 검색은 항공편 번호, 주식 시세 등을 자동으로 인식해 관련 정보를 제공.
- 효과: 더 정확하고 빠른 검색 결과 제공.
7. 교육
- 기능 및 활용 사례:
- 개인 맞춤형 학습 콘텐츠 제공.
- 자동화된 평가 시스템 개발로 교사의 업무 부담 감소.
- 효과:
- 학생들의 학습 효율성 향상.
- 학습자 행동 패턴 분석을 통한 학습 전략 최적화.
NLP 응용 분야별 비중
아래는 NLP 응용 분야의 사용 비중(2024년 기준)을 나타낸 도표의 주요 내용입니다:
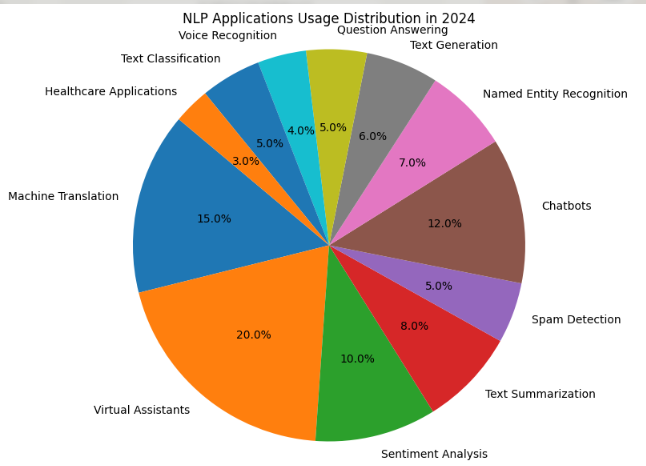
- 가상 비서(20%): 가장 큰 비중을 차지하며, 음성 명령 처리와 개인화된 서비스 제공에 활용됨.
- 기계 번역(15%): 다국어 실시간 번역 및 글로벌 커뮤니케이션 지원.
- 챗봇(12%): 고객 서비스 자동화와 실시간 상담에 사용됨.
- 감성 분석(10%): 소셜 미디어 및 리뷰 데이터를 분석해 기업 전략 수립에 기여.
- 자동 요약(8%): 긴 텍스트를 간결하게 요약해 정보 처리 효율성을 높임.
이 외에도 헬스케어, 스팸 탐지, 개체명 인식, 음성 인식 등 다양한 분야에서 NLP가 활용되고 있습니다.
최신 기술 동향
1. 초거대 언어 모델
- 개념: GPT 시리즈(OpenAI)와 같은 초거대 언어 모델은 대규모 데이터를 학습해 문맥 이해와 텍스트 생성을 정교하게 수행합니다.
- 주요 특징:
- OpenAI의 GPT-4는 다국어 지원과 멀티모달 기능(텍스트와 이미지를 함께 처리)을 제공하며, 다양한 산업에서 활용되고 있습니다.
- 2024년 출시된 GPT-4o는 기존 GPT-4보다 50% 저렴하고 2배 빠른 성능을 자랑하며, 텍스트 생성과 음성 응답 등 다양한 작업에서 효율성을 높였습니다.
- 응용 사례:
- 고객 지원 챗봇, 콘텐츠 생성, 번역 및 요약 작업.
- 예: Google의 Gemini 1.5는 다국어 번역과 텍스트 생성 작업에서 높은 정확도를 제공합니다.
2. 멀티모달 NLP
- 개념: 텍스트뿐만 아니라 이미지, 음성 데이터를 함께 처리하여 복합적인 작업을 수행하는 기술입니다.
- 주요 특징:
- OpenAI의 CLIP(Contrastive Language-Image Pre-training)은 텍스트와 이미지를 동시에 학습하여 이미지 캡션 생성 및 이미지 기반 질문 응답 작업을 수행합니다.
- 음성과 텍스트를 통합한 기술은 음성 명령 및 대화형 AI 시스템에서 활용됩니다.
- 응용 사례:
- 이미지 설명 생성: 예를 들어, 시각장애인을 위한 이미지 내용 설명.
- 비디오 요약: 긴 영상에서 핵심 내용을 자동으로 추출.
3. 실시간 데이터 처리
- 개념: 실시간으로 데이터를 분석하고 결과를 도출하는 기술로, 즉각적인 의사결정을 지원합니다.
- 주요 특징:
- 실시간 감성 분석: 소셜 미디어나 고객 리뷰 데이터를 실시간으로 분석해 소비자 반응을 파악.
- 금융 거래 분석: 이상 거래 탐지 및 리스크 관리.
- 응용 사례:
- 물류 분야에서는 IoT 센서와 GPS 데이터를 활용해 배송 상태를 실시간으로 추적하고 최적화합니다.
- 공공 서비스에서는 군중 패턴 분석과 소음 수준 모니터링으로 캠퍼스 환경을 개선.
4. 윤리적 AI와 데이터 편향 문제 해결
- 개념: NLP 모델의 공정성과 신뢰성을 높이기 위해 데이터 편향 문제를 해결하려는 연구가 활발히 진행 중입니다.
- 주요 특징:
- 데이터 다양화와 알고리즘 조정을 통해 불공정한 결과를 방지.
- 설계 단계부터 공정성을 고려한 “설계에 의한 공정성” 원칙 적용.
- 응용 사례:
- 민감한 데이터를 다룰 때 프라이버시 보호 및 차별 방지 조치 강화.
- 예: Anthropic의 Claude 3.5는 윤리적 설계를 기반으로 안전한 AI 상호작용을 제공합니다.
미래 전망
NLP 기술은 인간과 기계 간의 소통 방식을 혁신하며 점점 더 많은 산업에 적용되고 있습니다. 특히 초거대 언어 모델과 멀티모달 접근법의 발전은 더욱 정교하고 개인화된 서비스를 가능하게 하고 있습니다. 예를 들어:
- 교육 분야에서는 학생 맞춤형 학습 콘텐츠 제공과 자동화된 평가 시스템이 개발되고 있습니다.
- 헬스케어 분야에서는 의료 기록 분석과 질병 예측 시스템이 도입되어 의료 서비스 품질이 향상되고 있습니다.
- 금융 산업에서는 시장 데이터 분석과 리스크 관리를 통해 더 나은 투자 결정을 지원합니다.
또한 지속 가능한 발전 목표(SDGs) 달성을 위해 NLP가 환경 보호, 공공 보건, 교육 증진 등 다양한 분야에서 중요한 역할을 할 것으로 기대됩니다.
마무리
자연어 처리 기술은 끊임없이 진화하고 있습니다. 기본적인 텍스트 전처리부터 최신 트랜스포머 모델까지, 각 단계의 발전이 현재의 혁신적인 AI 서비스를 가능하게 했습니다. 특히 한국어처럼 복잡한 문법 구조를 가진 언어를 처리하는 데 있어서는, 언어의 특성을 고려한 세심한 접근이 필요합니다.
앞으로도 NLP 기술은 계속해서 발전할 것이며, 이는 우리의 삶을 더욱 편리하게 만들어줄 것입니다. 이러한 기술의 발전 속도가 매우 빠른 만큼, 개발자와 연구자들은 최신 트렌드를 지속적으로 학습하고 실제 적용 사례를 연구하는 것이 중요합니다. NLP는 이제 선택이 아닌 필수가 되었으며, 이를 효과적으로 활용하는 것이 미래 경쟁력의 핵심이 될 것입니다.




NLP 응용 분야의 사용 비중(2024년 기준)을 나타낸 도표에 대한 출처를 알 수 있을까요 ?
https://artsmart.ai/blog/natural-language-processing-nlp-statistics-2024/
포스트가 레퍼런스 이며, 2차 가공을 통해 도표로 생성되었습니다.